
As AI infrastructure grows beyond the limits of a single data center, connectivity requirements change fundamentally. Scale across addresses this challenge by extending AI systems across campuses and between geographically dispersed data centers. Understanding how coherent ZR and ZR+ enable high-bandwidth connectivity across tens, hundreds or thousands of kilometers is essential for building large scale AI infrastructure.
Across multiple generations, Marvell has set the pace for industry-first innovation—from introducing the first ZR module to leading 400G and 800G deployments and now extending leadership to 1.6T with advanced 2nm coherent DSPs.
The latest generation of Marvell coherent DSPs extends leadership into 2nm technology, including the industry’s first 1.6T ZR DSP and the first 800G ZR+ DSP with integrated MACsec security.
Scale across in AI infrastructure refers to extending AI systems beyond a single data center by connecting multiple sites across campuses, metropolitan areas, or geographic regions. At this stage, infrastructure growth is constrained less by compute density and more by physical limits such as power availability, cooling capacity, and facility footprint.
Unlike scale out, which focuses on cluster growth within a single data center, scale across enables AI systems to operate across multiple locations while maintaining coordinated operation.
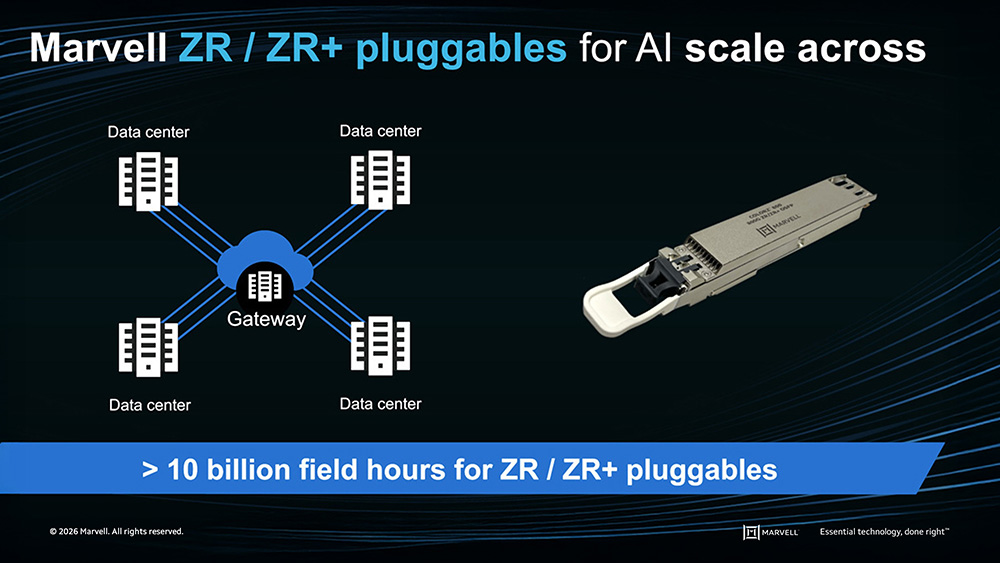 Scale-across extends AI infrastructure beyond a single data center, connecting campuses and regions using long-reach optical interconnects
Scale-across extends AI infrastructure beyond a single data center, connecting campuses and regions using long-reach optical interconnects
As AI deployments expand, the size of individual data centers increasingly reaches practical limits. These limits include available power and space, and operational constraints.
Scale across exists to:
By distributing infrastructure across locations, organizations can continue scaling AI systems even when single sites can no longer expand.
Scale across architectures connect AI infrastructure across longer distances than scale out systems.
These connections often span:
At these distances, electrical signaling is insufficient. Optical connectivity with advanced modulation and digital signal processing is required to maintain capacity, signal integrity, and reliability.
 Coherent ZR and ZR+ optics integrate advanced DSP and modulation to enable high-capacity data-center interconnect over regional and long-haul distances.
Coherent ZR and ZR+ optics integrate advanced DSP and modulation to enable high-capacity data-center interconnect over regional and long-haul distances.
Scale across connectivity is defined by the following characteristics:
These requirements fundamentally change the type of interconnect technologies used compared to scale-in, scale-up, and scale-out architectures.
Marvell has delivered industry-first coherent ZR solutions across multiple generations, combining power efficiency, integrated security, and production-scale manufacturing to support global AI infrastructure expansion.
Coherent ZR and ZR+ optical technologies integrate advanced digital signal processing and modulation to enable high-bandwidth data transmission over long distances.
With production 800G deployments and a roadmap extending to 1.6T on advanced 2nm process technology, Marvell coherent ZR platforms define the foundation of secure, low-power scale-across AI connectivity.
Coherent ZR and ZR+ enable scale across by:
While coherent technologies introduce additional complexity compared to short reach (PAM) optics, they are essential for achieving the reach and bandwidth required for scale across AI infrastructure.
In scale-across AI architectures, coherent ZR and ZR+ are commonly used:
These links form the backbone of large scale, multi-site AI deployments.
Scale across architectures are used by AI applications that require more infrastructure than can be housed in a single data center.
Common application categories include:
Different applications adopt scale across for different reasons, including capacity expansion, resiliency, and operational flexibility.
Scale across builds on earlier scaling stages:
Coherent ZR and ZR+ are most relevant at the scale across stage, where reach and capacity requirements exceed what shorter reach technologies can support.
Marvell develops platform technologies that are deployed across multiple layers of AI infrastructure. These platforms support different scaling requirements related to latency, bandwidth, reach, power efficiency, and system integration. The specific technologies used vary depending on the scaling model.
Marvell is the only company offering a comprehensive, hyperscale-optimized coherent DSP portfolio spanning campus and regional data center interconnect applications.
Marvell platform examples relevant to scale-across architectures include:
Scale across represents the outer boundary of AI infrastructure scaling. By extending systems across campuses, regions, and global networks, scale across enables continued AI growth beyond the limits of individual data centers. Coherent ZR and ZR+ technologies provide the reach, capacity, and interoperability required to support these deployments. As AI systems continue to expand, understanding scale across connectivity will remain critical for designing resilient and scalable AI infrastructure.
In addition to technology leadership, Marvell supports scale-across deployments with expanding high-volume manufacturing capacity designed to meet the accelerating global demand for AI infrastructure.
The Marvell coherent DSP portfolio spans production-ready 800G ZR deployments and next-generation 1.6T solutions built on advanced process technology, reinforcing leadership in secure, low-power scale-across connectivity.
Scale across refers to extending AI systems across multiple data centers or regions to overcome site-level constraints to enable continued expansion.
Scale out connects clusters within a single data center, while scale across connects infrastructure across multiple locations.
Long distances introduce loss and latency that electrical signaling cannot support, making optical and coherent technologies necessary.
Coherent ZR and ZR+ are optical technologies that use advanced modulation and digital signal processing to transmit data at high-bandwidth over long distances.
They are deployed between data centers, across campuses, and over regional or long-haul fiber networks.
Yes, distance introduces latency, which must be managed through system design and workload placement.
No. Scale across is used when site level limits are reached or when geographic distribution is required.
Geographic distribution improves fault isolation and enables more resilient AI infrastructure.