
By Marvell PR Team
Marvell shared its mission and focus on driving the core technology to enable the global network infrastructure at its recent investor day. This was followed up with an appearance at Nasdaq, where Matt Murphy, president and CEO of the company, rang the bell to open the stock exchange.

At both of these events in New York City, Marvell shared how far the company has come, where it was going, and reaffirmed its mission: To provide semiconductor solutions that process, move, store and secure the world’s data faster and more reliably than anyone else.
The world has become more connected and intelligent than ever, and the global network has also evolved at an astonishing rate. It’s imperative that the semiconductor industry advances even quicker to keep up with these new technology trends and stay relevant. Marvell recognizes that its customers, at the core or on the edge, face the daunting challenge of delivering solutions for this ever-changing world – today.
With both the breadth and depth of technology expertise, Marvell offers the critical technology elements — storage, Ethernet, Arm® processors, security processors and wireless connectivity — to drive innovation in the industry. With the Cavium acquisition, the company retains its strong and stable foothold while competing more aggressively and innovating faster to serve customers better.

For Marvell the future isn’t a distant challenge: it is here with us now, evolving at an accelerated pace. Marvell is enabling new technologies such as 5G, disrupting new Flash platform solutions for the data center, revolutionizing the in-car network, and developing new compute architectures for artificial intelligence, to name a few.

Bringing the most complete infrastructure portfolio of any semiconductor company, Marvell is more than ready to continue on its amazing journey, and have its customers and partners alongside it on the cutting-edge—today, tomorrow and beyond.
By Todd Owens, Field Marketing Director, Marvell
Converging network and storage I/O onto a single wire can drive significant cost reductions in the small to mid-size data center by reducing the number of connections required. Fewer adapter ports means fewer cables, optics and switch ports consumed, all of which reduce OPEX in the data center. Customers can take advantage of converged I/O by deploying Converged Network Adapters (CNA) that provide not only networking connectivity, but also provide storage offloads for iSCSI and FCoE as well.
Just recently, HPE has introduced two new CNAs based on Marvell® FastLinQ® 41000 Series technology. The HPE StoreFabric CN1200R 10GBASE-T Converged Network Adapter and HPE StoreFabric CN1300R 10/25Gb Converged Network Adapter are the latest additions in HPE’s CNA portfolio. These are the only HPE StoreFabric CNAs to also support Remote Direct Memory Access (RDMA) technology (concurrently with storage offloads).
As we all know, the amount of data being generated continues to increase and that data needs to be stored somewhere. Recently, we are seeing an increase in the number of iSCSI connected storage devices in mid-market, branch and campus environments. iSCSI is great for these environments because it is easy to deploy, it can run on standard Ethernet, and there are a variety of new iSCSI storage offerings available, like Nimble and MSA all flash storage arrays (AFAs).
One challenge with iSCSI is the load it puts on the Server CPU for storage traffic processing when using software initiators – a common approach to storage connectivity. To combat this, Storage Administrators can turn to CNAs with full iSCSI protocol offload. Offloading transfers the burden of processing the storage I/O from the CPU to the adapter. 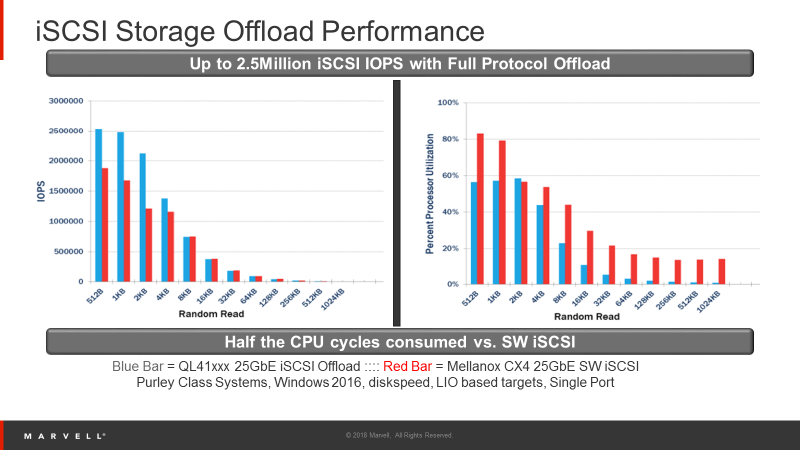 Figure 1: Benefits of Adapter Offloads
Figure 1: Benefits of Adapter Offloads
As Figure 1 shows, Marvell driven testing shows that CPU utilization using H/W offload in FastLinQ 10/25GbE adapters can reduce CPU utilization by as much as 50% compared to an Ethernet NIC with software initiators. This means less burden on the CPU, allowing you to add more virtual machines per server and potentially reducing the number of physical servers required. A small item like an intelligent I/O adapter from Marvell can provide a significant TCO savings.
Another challenge has been the latency associated with Ethernet connectivity. This can now be addressed with RDMA technology. iWARP, RDMA over Converged Ethernet (RoCE) and iSCSI over Ethernet with RDMA (iSER) all allow for I/O transactions to be performed directly from the memory to the adapter, bypassing the software kernel in the user space of the O/S. This speeds transactions and reduces the overall I/O latency. The result is better performance and faster applications.
The new HPE StoreFabric CNAs become the ideal devices for converging network and iSCSI storage traffic for HPE ProLiant and Apollo customers. The HPE StoreFabric CN1300R 10/25GbE CNA supports plenty of bandwidth that can be allocated to both the network and storage traffic. In addition, with support for Universal RDMA (support for both iWARP and RoCE) as well as iSER, this adapter provides significantly lower latency than standard network adapters for both the network and storage traffic.
The HPE StoreFabric 1300R also supports a technology Marvell calls SmartAN™, which allows the adapter to automatically configure itself when transitioning between 10GbE and 25GbE networks. This is key because at 25GbE speeds, Forward Error Correction (FEC) can be required, depending on the cabling used. To make things more complex, there are two different types of FEC that can be implemented. To eliminate all the complexity, SmartAN automatically configures the adapter to match the FEC, cabling and switch settings for either 10GbE or 25GbE connections, with no user intervention required.
When budget is the key concern, the HPE StoreFabric CN1200R is the perfect choice. Supporting 10GBASE-T connectivity, this adapter connects to existing CAT6A copper cabling using RJ-45 connections. This eliminates the need for more expensive DAC cables or optical transceivers. The StoreFabric CN1200R also supports RDMA protocols (iWARP, RoCE and iSER) for lower overall latency.
Why converge though? It’s all about a tradeoff between cost and performance. If we do the math to compare the cost of deploying separate LAN and storage networks versus a converged network, we can see that converging I/O greatly reduces the complexity of the infrastructure and can reduce acquisition costs by half. There are additional long-term cost savings also, associated with managing one network versus two. 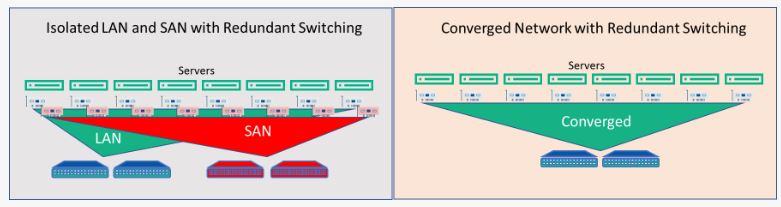 Figure 2: Eight Server Network Infrastructure Comparison
Figure 2: Eight Server Network Infrastructure Comparison
In this pricing scenario, we are looking at eight servers connecting to separate LAN and SAN environments versus connecting to a single converged environment as shown in figure 2. 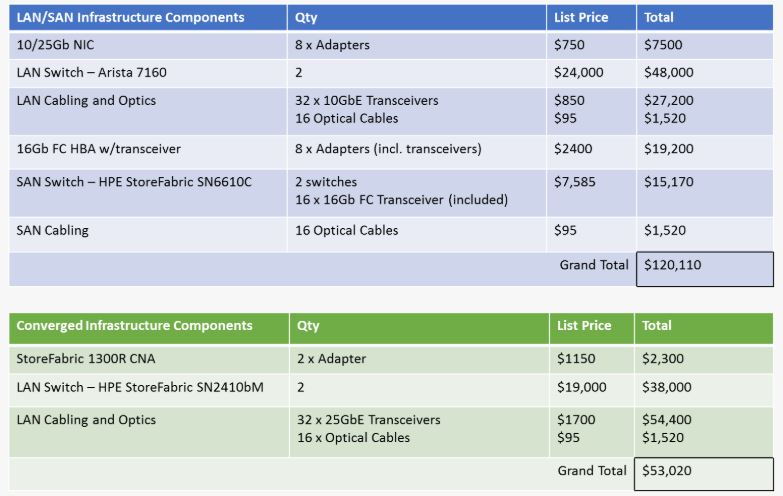 Table 1: LAN/SAN versus Converged Infrastructure Price Comparison
Table 1: LAN/SAN versus Converged Infrastructure Price Comparison
The converged environment price is 55% lower than the separate network approach. The downside is the potential storage performance impact of moving from a Fibre Channel SAN in the separate network environment to a converged iSCSI environment. The iSCSI performance can be increased by implementing a lossless Ethernet environment using Data Center Bridging and Priority Flow Control along with RoCE RDMA. This does add significant networking complexity but will improve the iSCSI performance by reducing the number of interrupts for storage traffic.
One additional scenario for these new adapters is in Hyper-Converged Infrastructure (HCI) implementations. With HCI, software defined storage is used. This means storage within the servers is shared across the network. Common implementations include Windows Storage Spaces Direct (S2D) and VMware vSAN Ready Node deployments. Both the HPE StoreFabric CN1200R BASE-T and CN1300R 10/25GbE CNAs are certified for use in either of these HCI implementations.  Figure 3: FastLinQ Technology Certified for Microsoft WSSD and VMware vSAN Ready Node
Figure 3: FastLinQ Technology Certified for Microsoft WSSD and VMware vSAN Ready Node
In summary, the new CNAs from the HPE StoreFabric group provide high performance, low cost connectivity for converged environments. With support for 10Gb and 25Gb Ethernet bandwidths, iWARP and RoCE RDMA and the ability to automatically negotiate changes between 10GbE and 25GbE connections with SmartAN™ technology, these are the ideal I/O connectivity options for small to mid-size server and storage networks. To get the most out over your server investments, choose Marvell FastLinQ Ethernet I/O technology which is engineered from the start with performance, total cost of ownership, flexibility and scalability in mind.
For more information on converged networking, contact one our HPE experts in the field to talk through your requirements. Just use the HPE Contact Information link on our HPE Microsite at www.marvell.com/hpe.
By Maen Suleiman, Senior Software Product Line Manager, Marvell and Gorka Garcia, Senior Lead Engineer, Marvell Semiconductor, Inc.
Thanks to the respective merits of its ARMADA® and OCTEON TX® multi-core processor offerings, Marvell is in a prime position to address a broad spectrum of demanding applications situated at the edge of the network. These applications can serve a multitude of markets that include small business, industrial and enterprise, and will require special technologies like efficient packet processing, machine learning and connectivity to the cloud. As part of its collaboration with Amazon Web Services® (AWS), Marvell will be illustrating the capabilities of edge computing applications through an exciting new demo that will be shown to attendees at Arm TechCon - which is being held at the San Jose Convention Center, October 16th-18th.
This demo takes the form of an automated parking lot. An ARMADA processor-based Marvell MACCHIATObin® community board, which integrates the AWS Greengrass® software, is used to serve as an edge compute node. The Marvell edge compute node receives video streams from two cameras that are placed at the entry gate and exit of the parking lot. The ARMADA processor-based compute node runs AWS Greengrass Core; executes two Lambda functions to process the incoming video streams and identify the vehicles entering the garage through their license plates; and subsequently checks whether the vehicles are authorized or unauthorized to enter the parking lot.
The first Lambda function will be running Automatic License Plate Recognition (OpenALPR) software and it obtains the license plate number and delivers it together with the gate ID (Entry/Exit) to a Lambda function running on the AWS® cloud that will access a DynamoDB® database. The cloud Lambda function will be responsible for reading the DynamoDB whitelist database and determines if the license plate belongs to an authorized car. This information will be sent back to a second Lambda function on the edge of the network, on the MACCHIATObin board, responsible for managing the parking lot capacity and opening or closing the gate. This Lambda function will be logging the activity in the edge to the AWS Cloud Elasticsearch® service, which works as a backend for Kibana®, an open source data visualization engine. Kibana will enable a remote operative to have direct access to information concerning parking lot occupancy, entry gate status and exit gate status. Furthermore, the AWS Cognito service authenticates users for access to Kibana. 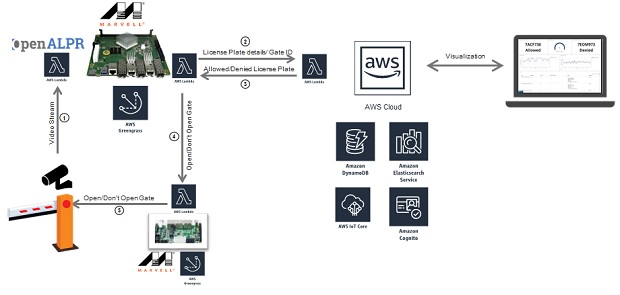
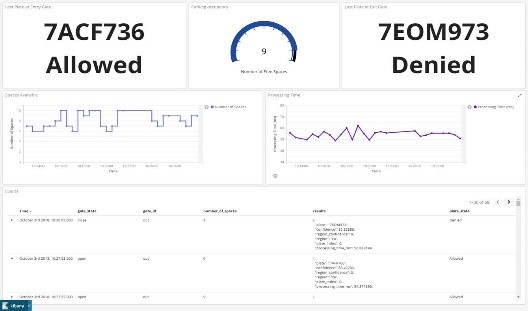
After the AWS Cloud Lambda function sends the verdict (allowed/denied) to the second Lambda function running on the MACCHIATObin board, this MACCHIATObin Lambda function will be responsible for communicating with the gate controller, which is comprised of a Marvell ESPRESSObin® board, and is used to open/close the gateway as required.
The ESPRESSObin board runs as an AWS Greengrass IoT device that will be responsible for opening the gate according to the information received from the MACCHIATObin board’s second Lambda function.
This demo showcases the capabilities to run a machine learning algorithm using AWS Lambda at the edge to make the identification process extremely fast. This is possible through the high performance, low-power Marvell OCTEON TX and ARMADA multi-core processors. Marvell infrastructure processors’ capabilities have the potential to cover a range of higher-end networking and security applications that can benefit from the maturity of the Arm® ecosystem and the ability to run machine learning in a multi-core environment at the edge of the network.
Those visiting the Arm Infrastructure Pavilion (Booth# 216) at Arm TechCon (San Jose Convention Center, October 16th-18th) will be able to see the Marvell Edge Computing demo powered by AWS Greengrass.
For information on how to enable AWS Greengrass on Marvell MACCHIATObin and Marvell ESPRESSObin community boards, please visit http://wiki.macchiatobin.net/tiki-index.php?page=AWS+Greengrass+on+MACCHIATObin and http://wiki.espressobin.net/tiki-index.php?page=AWS+Greengrass+on+ESPRESSObin.
