
AI is all about dichotomies. Distinct computing architectures and processors have been developed for training and inference workloads. In the past two years, scale-up and scale-out networks have emerged.
Soon, the same will happen in storage.
The AI infrastructure need is prompting storage companies to develop SSDs, controllers, NAND and other technologies fine-tuned to support GPUs—with an emphasis on higher IOPS (input/output operations per second) for AI inference—that will be fundamentally different from those for CPU-connected drives where latency and capacity are the bigger focus points. This drive bifurcation also likely won’t be the last; expect to also see drives optimized for training or inference.
As in other technology markets, the changes are being driven by the rapid growth of AI and the equally rapidly growing need to boost the performance, efficiency and TCO of AI infrastructure. The total amount of SSD capacity inside data centers is expected to double to approximately 2 zettabytes by 2028 with the growth primary fueled by AI.1 By that year, SSDs will account for 41% of the installed base of data center drives, up from 25% in 2023.1
Greater storage capacity, however, also potentially means more storage network complexity, latency, and storage management overhead. It also means potentially more power. In 2023, SSDs accounted for 4 terawatt hours of data center power, or around 25% of the 16 TWh consumed by storage. By 2028, SSDs are slated to account for 11TWh, or 50%, of storage’s expected total for the year.1 While storage represents less than five percent of total data power consumption, the total remains large and provides incentives for saving. Reducing storage power by even 1 TWh, or less than 10%, would save enough electricity to power 90,000 US homes for a year.2 Finding the precise balance between capacity, speed, power and cost will be critical for both AI data center operators and customers. Creating different categories of technologies becomes the first step toward optimizing products in a way that will be scalable.
The initial impulse when thinking about storage is to split it along familiar lines like training and inference or scale-up and scale-out. The dividing line between storage types is ultimately rooted in the processors that will initiate storage accesses driven by AI workloads, i.e. storage loads become GPU-initiated or CPU-initiated. GPU-initiated storage is often linked with inference workloads and CPU-initiated storage with training, but not always. GPU- and CPU-initiated storage requests can begin with a request for data in a local SSD or the remote SSDs. The data flow is bidirectional. The key issue, again, is which processor initiates the request.
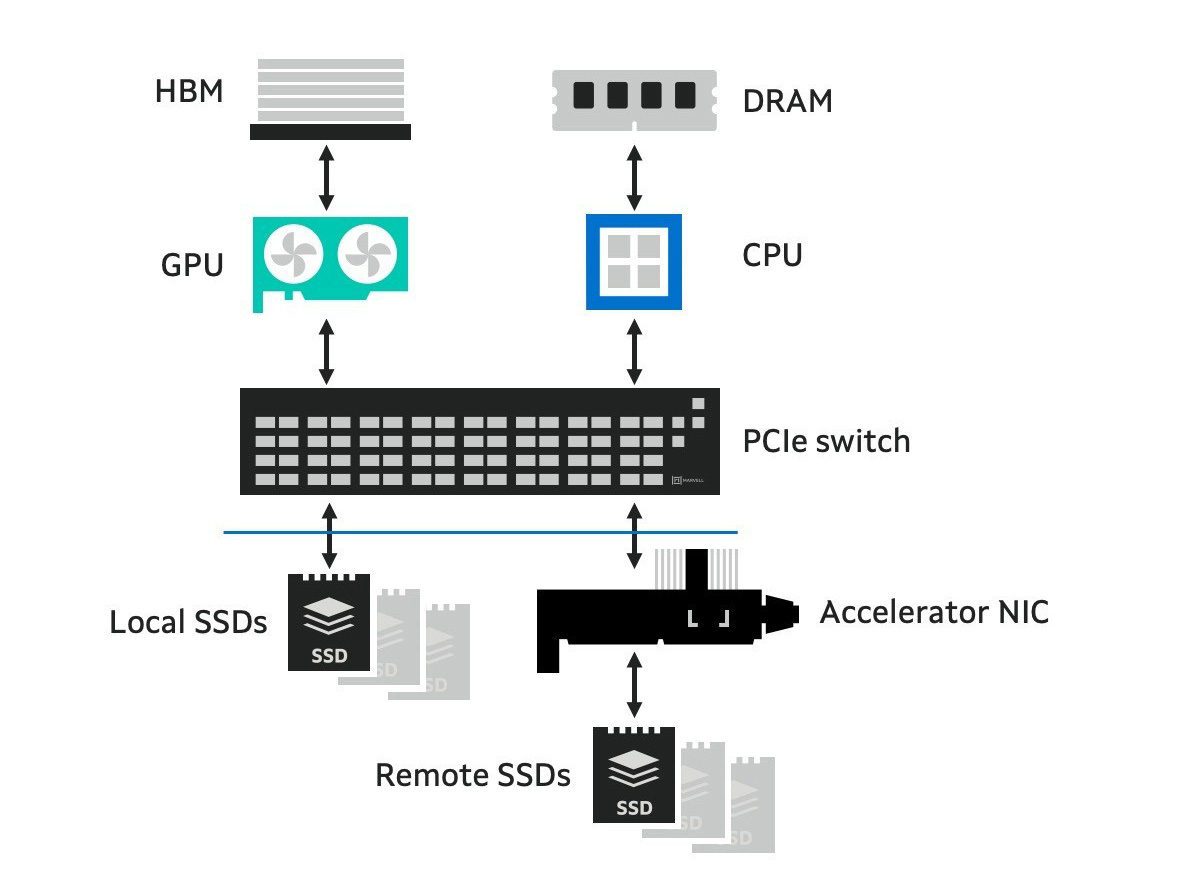
GPU/CPU storage architecture: GPUs or CPUs can access local or remote SSDs to initiate a storage request.
GPU-initiated Storage
In each tray of scale-up AI environments, multiple SSDs (currently up to eight) are directly attached to GPUs (currently up to four) via PCIe bus behind a PCIe switch. The GPU initiates storage transactions within the SCADA framework which is built around memory semantics.
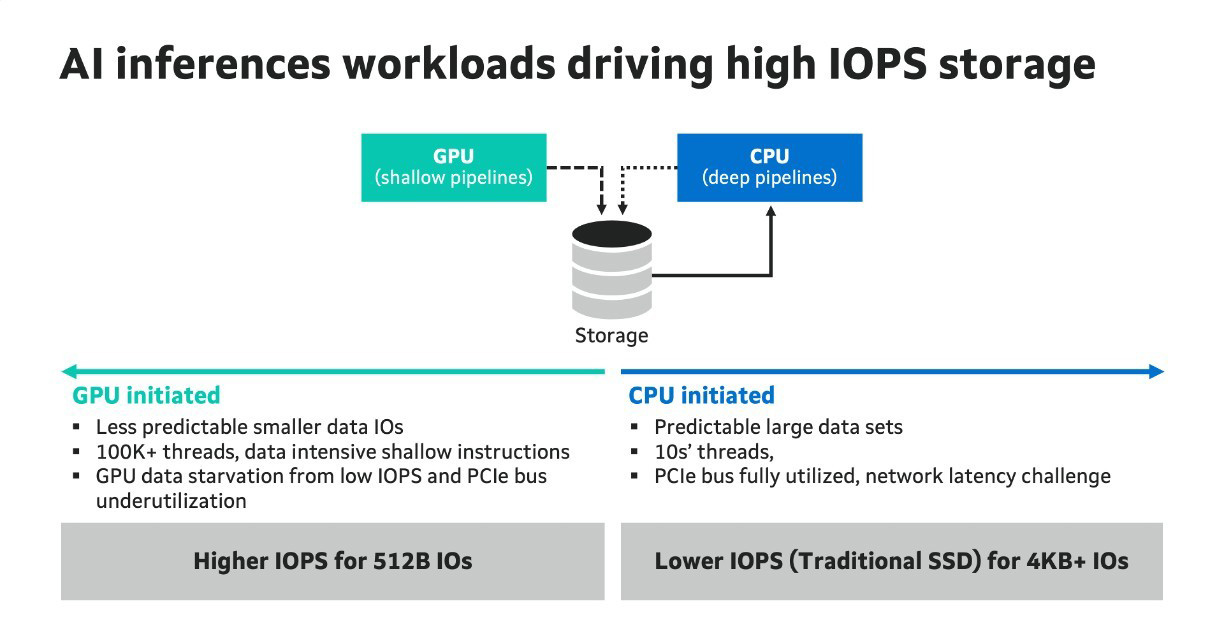
For AI inferences workloads, the GPU is working on over one thousand data intensive parallel threads, which typically requires smaller data sets, and not being able to get these data sets at the required speed leads to underutilization of expensive GPU cycles.
The current generation of SSDs are not able to scale IOPS for data sets smaller than 4KB which results in an underutilized PCIe bus, leading to the GPU starving for data and wasting cycles. As of now, this is being accomplished by deploying more parallel SSDs, which increases both the system cost and power while still not being able to deliver the target performance. To solve this, NVIDIA has outlined the “Storage-Next” architecture that will require PCIe 7.0 SSDs to operate at 100 million IOPS.3
Flash media providers are working on faster low-latency NAND media, but the bigger, more impactful changes will occur within flash storage controllers where Marvell is an established leader. These new flash controllers will not only need accelerator functions, but also optimal error correction schemes for smaller payloads. Given that Marvell has a strong portfolio for accelerators, multi-NAND support and advanced DSP capabilities, the company is well positioned to address the high-performance needs of next generation AI storage.
CPU-initiated Storage
In a CPU-initiated storage environment, workloads are typically for AI training, and the number of GPU parallel threads is much lower—tens versus thousands—and data sets are larger in size. For larger data sizes and IOPS, there is full utilization of the GPU PCIe bus, as with 4KB IO and a 7 million IOPS PCIe 6.0 SSD, 28GB/s throughput is achieved.4 But as the storage is behind the network, there is a need to improve the latency of data. This latency is also being contributed by the Ethernet to PCIe storage layer translations.
The most notable shift, however, will revolve around drives that are capable of handling both PCIe and Ethernet traffic. Unlike the cloud era, competing networking protocols will likely exist side-by-side in many environments, just like in many of the networking and processing products that Marvell already ships in high volumes.
Below is a summary of the primary distinctions between GPU-initiated and CPU-initiated storage:
Further Changes
Optimization and customization will certainly continue beyond what’s outlined above. AI training drives, whether for scale-up or scale-out networks, will be fine-tuned for computationally intensive environments while high IOPS drives will be demanded by inference workloads. Expect to see future work on interfacing with high bandwidth flash memory or CXL networks. Hard drives will also undergo a similar transformation.
Perhaps the most accurate prediction that one can make is that in the quest for better AI infrastructure, every link in the storage value chain will be mined for gains.
# # #
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: AI, AI infrastructure, storage, data storage, SSD controllers
