
Last week, Marvell introduced Nova™, its latest, fourth generation PAM4 DSP for optical modules. It features breakthrough 200G per lambda optical bandwidth, which enables the module ecosystem to bring to market 1.6 Tbps pluggable modules. You can read more about it in the press release and the product brief.
In this post, I’ll explain why the optical modules enabled by Nova are the optimal solution to high-bandwidth connectivity in artificial intelligence and machine learning systems.
Let’s begin with a look into the architecture of supercomputers, also known as high-performance computing (HPC).
Historically, HPC has been realized using large-scale computer clusters interconnected by high-speed, low-latency communications networks to act as a single computer. Such systems are found in national or university laboratories and are used to simulate complex physics and chemistry to aid groundbreaking research in areas such as nuclear fusion, climate modeling and drug discovery. They consume megawatts of power.
The introduction of graphics processing units (GPUs) has provided a more efficient way to complete specific types of computationally intensive workloads. GPUs allow for the use of massive, multi-core parallel processing, while central processing units (CPUs) execute serial processes within each core. GPUs have both improved HPC performance for scientific research purposes and enabled a machine learning (ML) renaissance of sorts. With these advances, artificial intelligence (AI) is being pursued in earnest.
Of course, not all machine learning is artificial intelligence. Pure ML applications include search engine results and content recommendations common in social media applications. AI/ML examples include natural language processing applications such as Apple’s Siri, Amazon’s Alexa, or emerging applications like OpenAI’s ChatGPT.
To achieve “artificial intelligence” with ML, specialized HPC systems are used to train ML algorithms (aka “deep learning”) using extremely large data sets comprised of books, articles, and web content. The result is a mathematical model that can predict the probability of a given sequence of words occurring in a given context. These large language models (LLM), as they are known, have grown exponentially in scale over the past five years and are now set to surpass trillions of parameters.
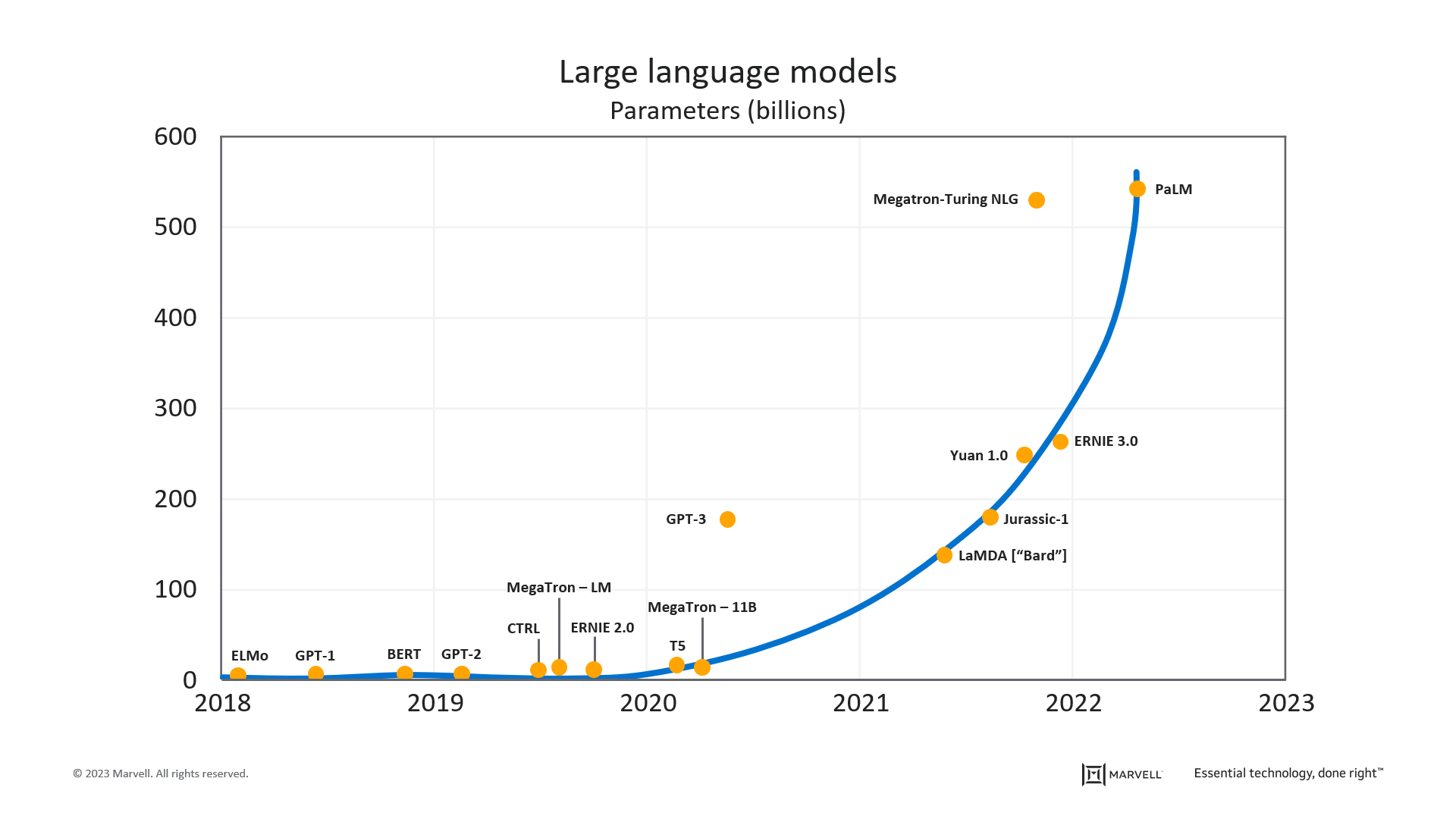
Marvell estimates based on data from Dr. Alan D. Thompson, LifeArchitect.ai (Dec. 2022-Mar. 2023).
The growth of such ML models is driving a 100-fold increase in network bandwidth requirements within the HPC instances executing the training.
As a consequence, ML training models are the driving force behind technology roadmaps for high-speed communications. These exaFLOP-scale systems require thousands of networking connections to tie all the compute resources together—while minimizing latency between any two points in the system.
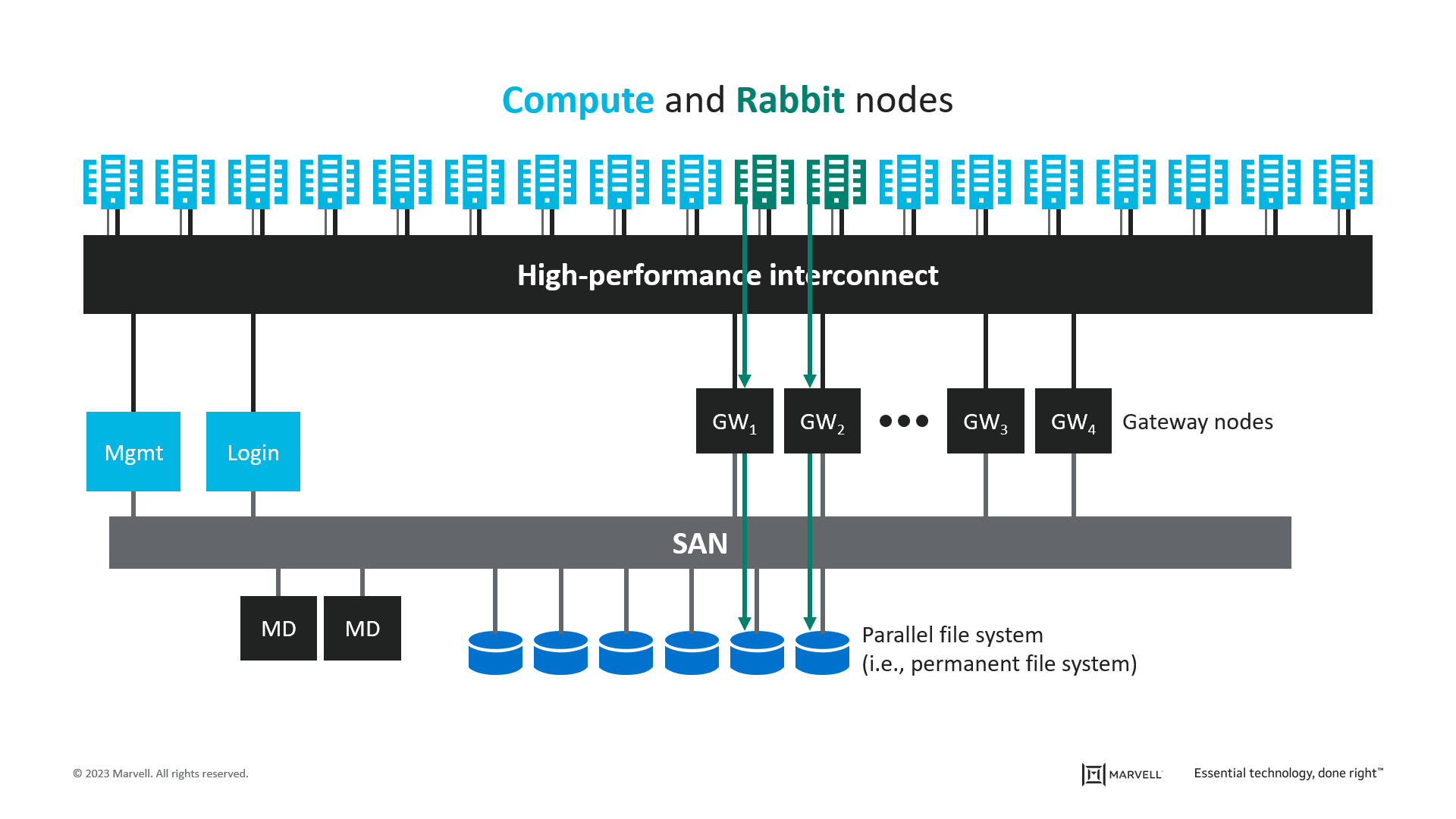
Lawrence Livermore National Laboratory’s “El Capitan” HPC [HPE/Cray est. >2 exaFLOPS]
For the next generation of AI/ML training and HPC systems, operators will require optical interconnects to support communications between entire compute chassis. These ultra-high-performance interconnects must scale to production quickly, demonstrate reliability and incur minimal technology and deployment risk.
Marvell’s Nova optical DSP for 1.6 Tbps pluggable transceivers is the ideal solution to address operators’ requirements. Let me explain why.
High-speed, low-latency performance
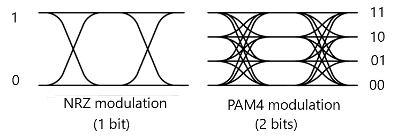
Nova, which doubles optical bandwidth compared to existing solutions, provides 8x 200 Gbps optical transmission using PAM4 modulation with four power levels, each representing two bits per clock cycle. The host side provides a 16x 100 Gbps electrical interface aligned to current IEEE/OIF interface standards to support PCIe Gen 5 memory bus architectures.
Integrated laser drivers reduce transceiver complexity and reduce cost. Concatenated forward error correction (FEC) provides additional link margin for higher electrical interface bit error rates (BER). Repeatable, low latency operation meets stringent AI/ML interconnect requirements.
Ability to scale
By conducting optical transmission at 8x 200 Gbps/channel, the data rate over each fiber pair is doubled compared to 100 Gbps/channel systems, reducing required fiber count and optical components by 50%. The optical component count savings reduces manufacturing complexity improving manufacturing yields while also reducing test equipment CAPEX needed to support volume production.
Furthermore, the use of pluggable transceivers offers a high degree of supply chain flexibility compared to potential alternatives. The module ecosystem includes 30+ vendors with more than a quarter century of experience building pluggable transceivers, beginning with the 1 Gbps GBIC form-factor of the late 1990s. The presence of this ecosystem ensures a rapid production ramp to the required interconnect volumes, while inter-vendor competition ensures competitive prices.
Reliable operation
There is another benefit to Nova’s 50% reduction in component count: a nearly 2x expected improvement in failures in time (FIT) reliability. History has shown that approximately 90% of optical transceiver failure modes are associated with the optical components themselves. By combining reduced component count with well-established manufacturing processes, the pluggable ecosystem is expected to minimize random failure rates. And for operators, making use of existing trained installation/maintenance technicians minimizes failures due to improper handling—failures that lead to unplanned delays and unplanned CAPEX/OPEX.
Pluggable modules: the ideal complement to AI/ML computing
AI/ML and HPC systems exhibit unique requirements that vary significantly from those of the “classic” data center. A 12-month or longer delay to a planned system deployment can render the entire compute architecture obsolete, giving competitors a significant market advantage.
In the words of the band Talking Heads, “this ain't no party, this ain't no disco, this ain't no fooling around.”
Any interconnect technology deployed in cutting-edge, potentially exascale computing environments must be proven. That means:
Pluggable modules check these boxes today. The path to commercialize 200G PAM4 DSP-based transceivers is well-trod by the generations that came before. Operators also maintain the flexibility to deploy low-cost, low-power copper interconnects for short reaches in a common form factor used for optical interconnects.
Net: the risks are low; the benefits are high, 200G/lambda is ready for commercial volumes. Pluggable transceivers are, thus, the most practical interconnect solution for AI/ML training and HPC systems planned for deployment in the next few years.
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
