
Can AI beat a human at the game of twenty questions? Yes.
And can a server enhanced by CXL beat an AI server without it? Yes, and by a wide margin.
While CXL technology was originally developed for general-purpose cloud servers, the technology is now finding a home in AI as a vehicle for economically and efficiently boosting the performance of AI infrastructure. To this end, Marvell has been conducting benchmark tests on different AI use cases.
In December, Marvell, Samsung and Liqid showed how Marvell® StructeraTM A CXL compute accelerators can reduce the time required for conducting vector searches (for analyzing unstructured data within documents) by more than 5x.
In February, Marvell showed how a trio of Structera A CXL compute accelerators can process more queries per second than a cutting-edge server CPU and at a lower latency while leaving the host CPU open for different computing tasks.
Today, this blog post will show how Structera CXL memory expanders can boost performance of inference tasks.
AI and Memory Expansion
Unlike CXL compute accelerators, CXL memory expanders do not contain additional processing cores for near-memory computing. Instead, they supersize memory capacity and bandwidth. Marvell Structera X, released last year, provides a path for adding up to 4TB of DDR5 DRAM or 6TB of DDR4 DRAM to servers (12TB with integrated LZ4 compression) along with 200GB/second of additional bandwidth. Multiple Structera X modules, moreover, can be added to a single server; CXL modules slot into PCIe ports rather than the more limited DIMM slots used for memory.

A Structera X board fully populated with DDR4 memory DIMMs along with samples of Structera X memory expanders for DDR5 (bottom) and DDR4 (top). Structera X consumes < 30 watts. Deploying an extra CPU or XPU (150W-700W) to gain memory slots would inflate the power envelope. 1
Time-to-first-token (TTFT) is arguably the most critical metric when it comes to inference. A “token” is essentially an answer to a query. XPUs retrieve data from attached memory, perform calculations, transmit the results and the amalgamated answer is delivered to consumers.
TTFT, however, requires large amounts of data, forcing the XPU to frequently flush existing data from the Key-Value (KV) cache and/or retrieve new data from storage. If the user has filed multiple queries, data retrieval can become a time- and energy-consuming process with the processor reloading the same data into memory multiple times. CXL memory expanders substantially boost the capacity of the KV cache, streamlining workloads and reducing processing times.
To Hell and Back, Metaphorically Speaking
What’s a real-world use case involving multiple, interrelated queries? Homework. We fed a series of newspaper editorials along with copy of Dante’s Inferno into a Llama 3.1 LLM with 8 billion parameters and asked it to answer a series of 20 questions: who is the author? what is his or her primary point? etc. Each question or token required the hardware systems to rescan the entire book along with previous answers.
A GPU with 36.4GB of active HBM analyzed the editorials, while an identical system containing a Structera X card containing 64GB of memory and 100 Gbps of memory bandwidth, or about 1/20th of its total memory capacity and 1/2 the total bandwidth, had to interpret the 14th Century narrative poem about a voyage through the Nine Circles of the World (without Cliff’s Notes).
The results: The unaided system completed each question in 1.9 seconds on average. The system containing the Structera X board did the task 0.51 seconds.
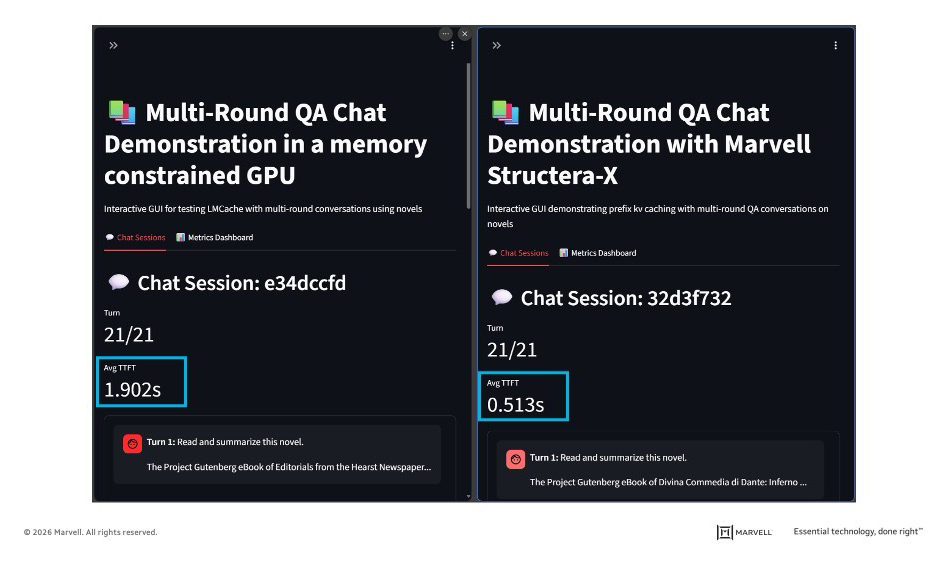
Because of the additional memory capacity and bandwidth, the Structera X-enhanced system can generation tokens in 74% less time, time savings that can improve infrastructure ROI.
And to prove Inferno wasn’t a one-off exception, we ran the test on other classics. The GPU-based system clocked a TTFT average of 1.995 seconds on The Secret Garden while the CXL-enhanced version came in more than 3x faster at 0.628 seconds. Anne’s House of Dreams, the fifth in the Anne of Green Gables Series? Structera X wins again, 0.572 seconds for average TTFT to 1.825 compared to the unaided system.
On to the Economics Homework
In a one-off homework assignment, the time savings might sound negligible. Across a worldwide network of data centers answering millions of queries daily, those seconds add up to substantial savings in processing time. Faster TTFT becomes a pathway to increasing utilization, reducing idle time, boosting work performed per watt consumed and ultimately improving total cost of ownership and/or return on investment.
Marvell Structera X memory expanders can improve the bottom line in other ways as well. Because it is compatible with DDR4, service providers can populate Structera X with memory from discontinued DDR4-based servers they might already own. In other words, memory acquisition costs plummet to zero. By contrast, a 128GB DDR DIMMs in the spot market sold for $3808 in January 2025,2 over 50% higher than the $2,488 prices of 2024. Repurposing existing memory also reduces e-waste. Equipping 30 servers in a rack would run just over $100,000. A single row of ten racks? $1 million.
Repurposing is good for the environment too. Manufacturing 1GB of DRAM generates between 3kg and 5kg of CO2. Avoiding the production of 12TB of DRAM is the equivalent of taking up to 14 gasoline engine cars or 52 EVs off the road for a year.3

Patrick Kennedy of ServeTheHome runs the benchmarks for Structera X and Structera A in this video.
The CXL Renaissance
In 2025, networking was often touted as the bottleneck to greater computing performance. In 2026, the focus has shifted to memory. CXL provides developers a path forward by giving them a way to add large amounts of memory—and in many cases less expensive memory—to servers already on the market. Expect to see more use cases as the market discovers what can be accomplished with this technology.
1. Power consumption of Structera provided from Marvell. CPU and XPU power ceilings averaged from data posted by vendors.
2. Memory.Net
3. EPA Greenhouse gas equivalency calculator. 5kg per 1GB x 12TB = 60,000kg.
# # #
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: memory, AI, AI infrastructure, data centers
