
PCIe has historically been used as protocol for communication between CPU and computer subsystems. It has gradually increased speed since its debut in 2003 (PCI Express) and after 20 years of PCIe development, we are currently at PCIe Gen 5 with I/O bandwidth of 32Gbps per lane. There are many factors driving the PCIe speed increase. The most prominent ones are artificial intelligence (AI) and machine learning (ML). In order for CPU and AI Accelerators/GPUs to effectively work with each other for larger training models, the communication bandwidth of the PCIe-based interconnects between them needs to scale to keep up with the exponentially increasing size of parameters and data sets used in AI models. As the number of PCIe lanes supported increases with each generation, the physical constraints of the package beachfront and PCB routing put a limit to the maximum number of lanes in a system. This leaves I/O speed increase as the only way to push more data transactions per second. The compute interconnect bandwidth demand fueled by AI and ML is driving a faster transition to the next generation of PCIe, which is PCIe Gen 6.
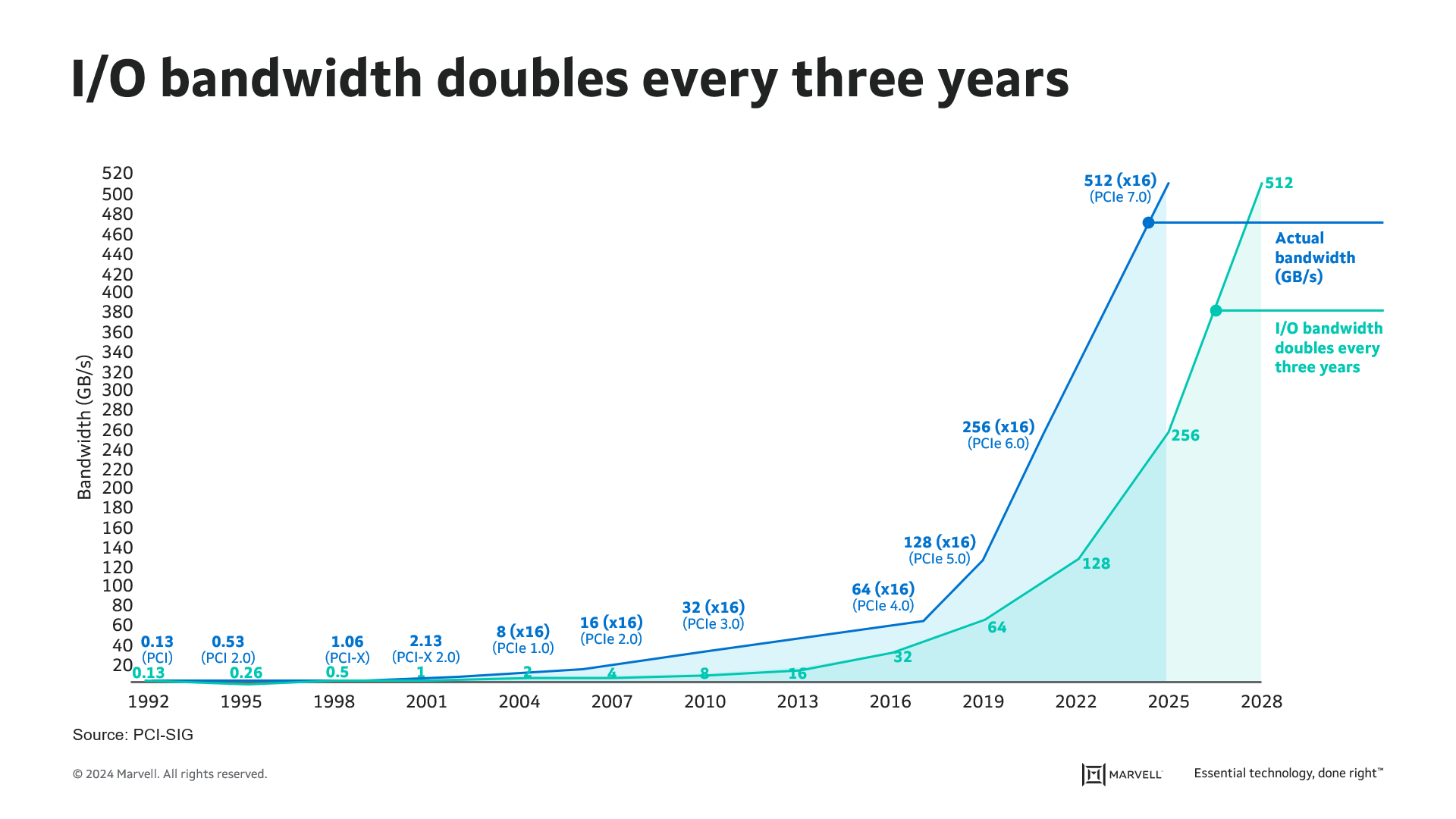
PCIe has been using 2-level Non-Return-to-Zero (NRZ) modulation since its inception. Increasing PCIe speed up to Gen 5 has been achieved through doubling of the I/O speed. For Gen 6, PCI-SIG decided to adopt Pulse-Amplitude Modulation 4 (PAM4), which carries 4-level signal encoding 2 bits of data (00, 01, 10, 11). The reduced margin resulting from the transition of 2-level signaling to 4-level signaling has also necessitated the use of Forward Error Correction (FEC) protection, a first for PCIe links. With the adoptions of PAM4 signaling and FEC, Gen 6 marks an inflection point for PCIe both from signaling and protocol layer perspectives.
In addition to AI/ML, disaggregation of memory and storage is an emerging trend in compute applications that has a significant impact in the applications of PCIe based interconnect. PCIe has historically been adopted on-board and for in-chassis interconnects. Attaching more front-facing NVMe SSDs is one of the common PCIe interconnect examples. With the increasing trends toward flexible resource allocation, and the advancement of CXL technology, the server industry is now moving toward disaggregated and composable infrastructure. In this disaggregated architecture, the PCIe end points are located at different chassis away from the PCIe root complex, requiring the PCIe link to travel out of the system chassis. This is typically achieved through direct attach cables (DAC) that can range up to 3-5m.
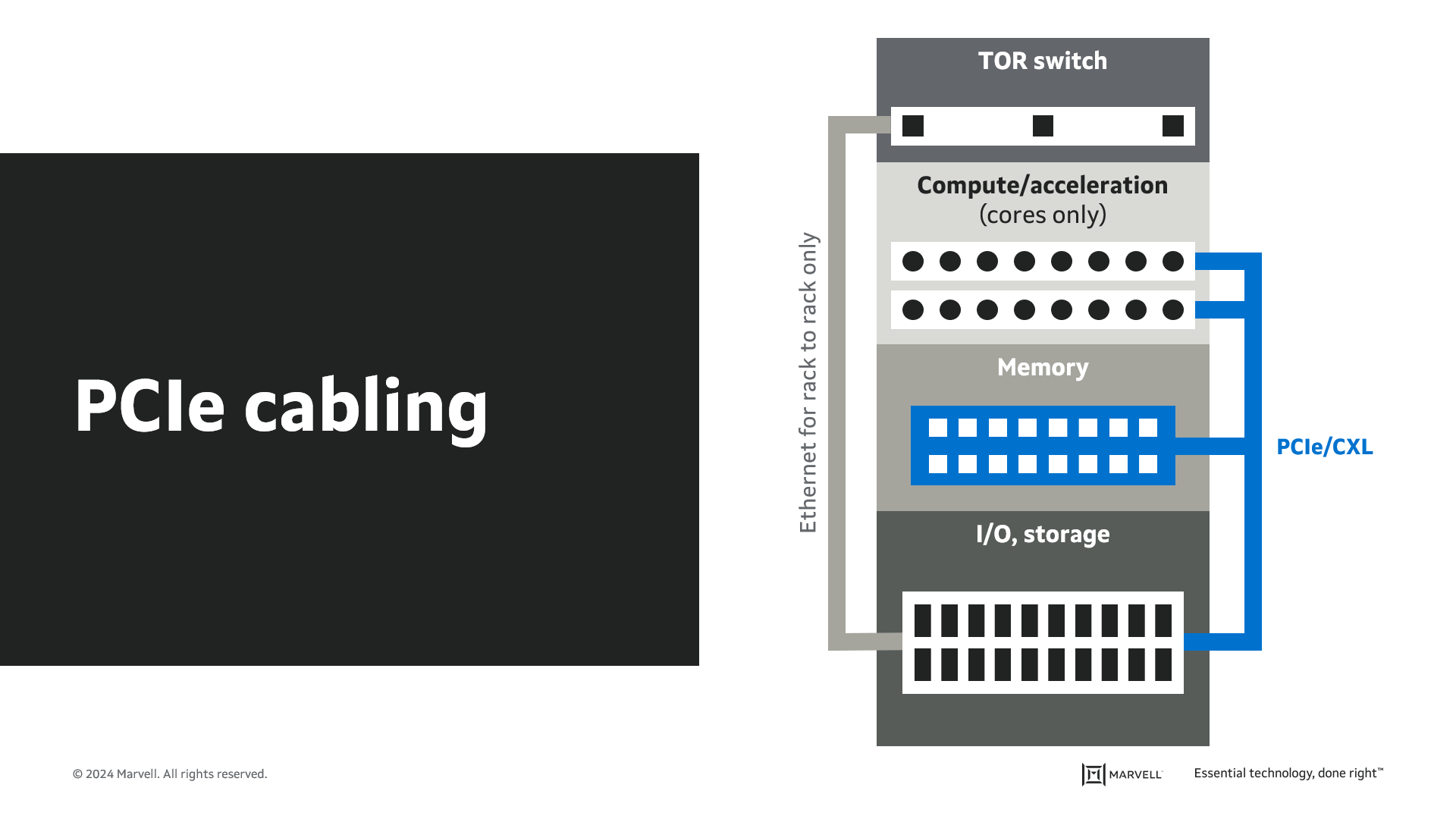
The reach capability of the SerDes on the CPU or Accelerator/GPU is typically limited to driving links within a chassis. The longer reach needed for these emerging disaggregated applications requires alternative approaches such as the use of expensive, low loss board material or the use of external retimers to regenerate the signal. Retimers provide a much more flexible and economical solution compared to the use of lowest loss PCB materials.
The reach extension achieved by an external retimer is determined by the equalization capability of the receiver in the retimer. During the recent 2023 OCP Summit with the cooperation of TE Connectivity, Marvell demonstrated a 4m passive copper cable driven by Marvell’s PCIe Gen 6 silicon on both ends.
Below is the end-to-end channel topology of this PCIe Gen 6 silicon demo and a photo of the demo in action.
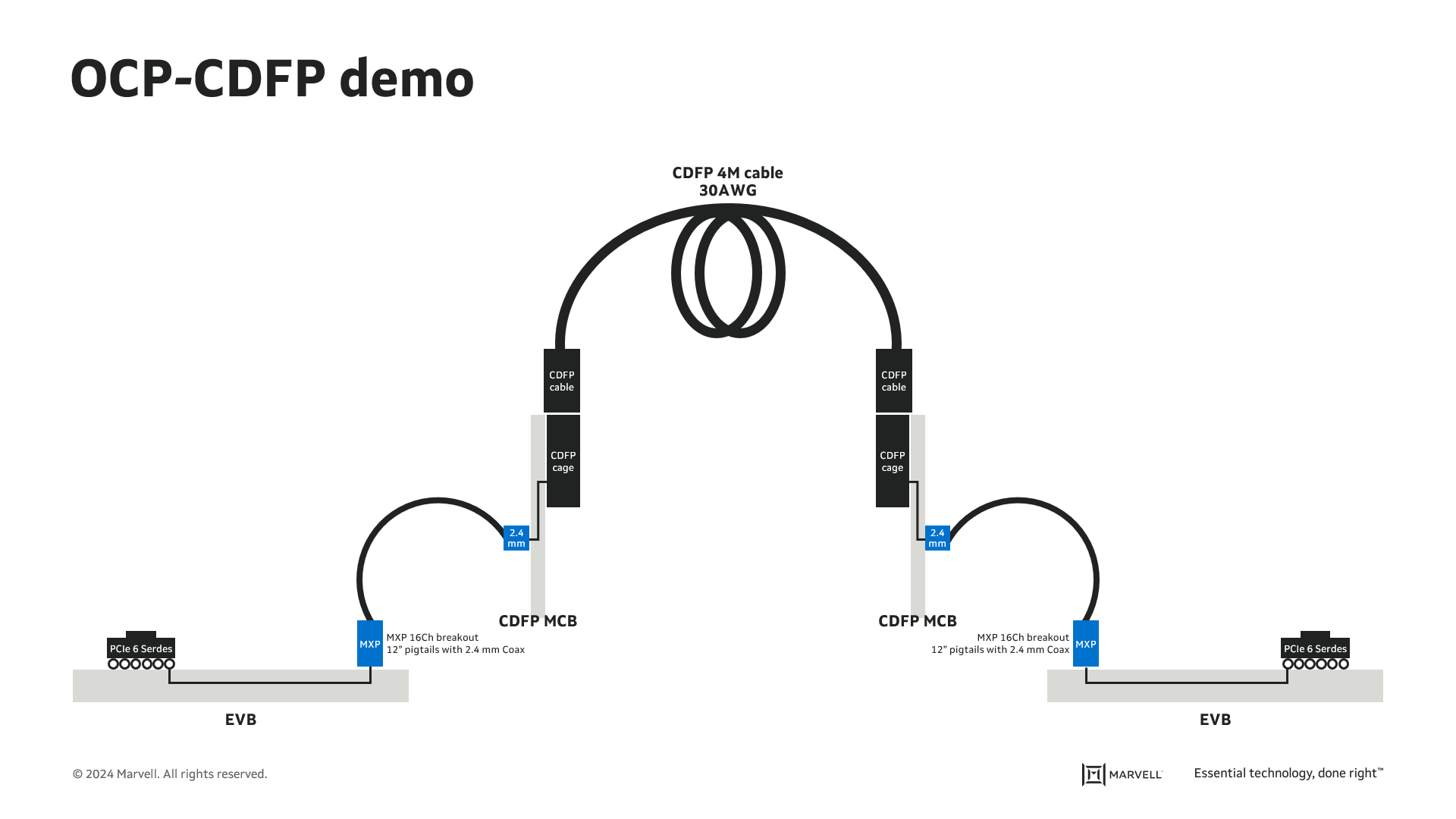

The end-to-end BER for the 4m 30AWG cable was measured at 1E-11, delivering 5 orders of magnitude in margin compared to the PCIe requirement of 1E-6 for the post-FEC BER.
The whitepaper published by TE about a similar demo at DesignCon’23 provides additional details of the cabled PCIe links and the demo setup.
TE will be demonstrating this 4m cabled PCIe demo at the DesignCon’24 show, taking place January 30-Febrary 1 in Santa Clara. If you missed the demo at OCP Global Summit, please visit the TE booth at DesignCon’24.
Marvell is the leader in PAM4 I/Os with the support of speeds up to 224G/lane for Ethernet applications. Marvell has leveraged this deep expertise in PAM4 I/Os to deliver industry leading equalization performance on its 64G PAM4 I/O optimized for power, performance, and latency requirements of PCIe 6 reach-extension applications. The performance of the Marvell SerDes enables longer reaches required for the emerging disaggregation applications, with the link margin necessary for robust operation in large scale deployments. There are exciting activities around PCIe external connectivity, including multiple working groups within PCI-SIG, OCP and SNIA. The next step beyond passive PCIe cables is expected to be “active” PCIe cable (AEC, Active Electrical Cable), which integrates PCIe retimers into cable connectors to drive longer cable reach. At the same time the industry is also looking into optical PCIe, with the goal to extend the reach of external PCIe connectivity and unlock full potential of PCIe interconnects.
Compute interconnect and PCIe is going through a phase of disruption and rapid innovation. Marvell is positioned to play an important role in enabling the evolution of PCIe interconnects by delivering optimized copper and optical connectivity solutions.
Tags: Connectivity, Intelligent Connectivity, Optical Connectivity, PCIe
