
The AI memory wall—the widening gap between the memory capacity and bandwidth AI infrastructure wants and the amount that conventional memory architectures can deliver—is accelerating at an alarming pace.
And the consequences are getting increasingly ominous for data center operators and their customers: idle XPUs, underutilized equipment, longer processing times, higher costs, and ultimately a lower return on investment. Meanwhile, memory—already second only to GPUs in datacenter semiconductor spend1—continues to soar in price.
The Marvell® StructeraTM S family of Compute Express Link (CXL) switches scale the memory wall by providing a pathway for adding terabytes of shareable memory to infrastructure and dynamically allocating bandwidth and capacity to boost utilization and application performance. CXL switches don’t just boost memory and memory capacity; they enable data center operators to use it more wisely too.
Structera S is the successor to the groundbreaking Apollo line of CXL switches developed by XConn Technologies, now part of Marvell. Structera S 20256 for PCIe 5.0/CXL 2.0 (previously the XConn Apollo I) became the first commercially available CXL switch upon its release last year.
Marvell is expanding the family with Structera S 30260 for PCIe 6.0/CXL 3.x. Structera S 30260 features support for 16 or 32 CPUs or GPUs over 260 lanes with up to 48TB of shared memory and 4TB/second cumulative bandwidth. Marvell is showcasing Structera S 30260 in a live demonstration this week at OFC 2026 and plans on sampling to customers in 3Q 2026.
Changing the (Memory) Channel
CXL overcomes the memory wall by going around it. Instead of adding more processors or increasing the size of HBM stacks, CXL adds memory via available PCIe channels on a host CPU, GPU or XPU. Adding shareable DRAM via CXL switches improves memory utilization, simplifies data transfer, streamlines programming models and reduces power consumption while simultaneously maintaining stringent levels of data access and isolation.2
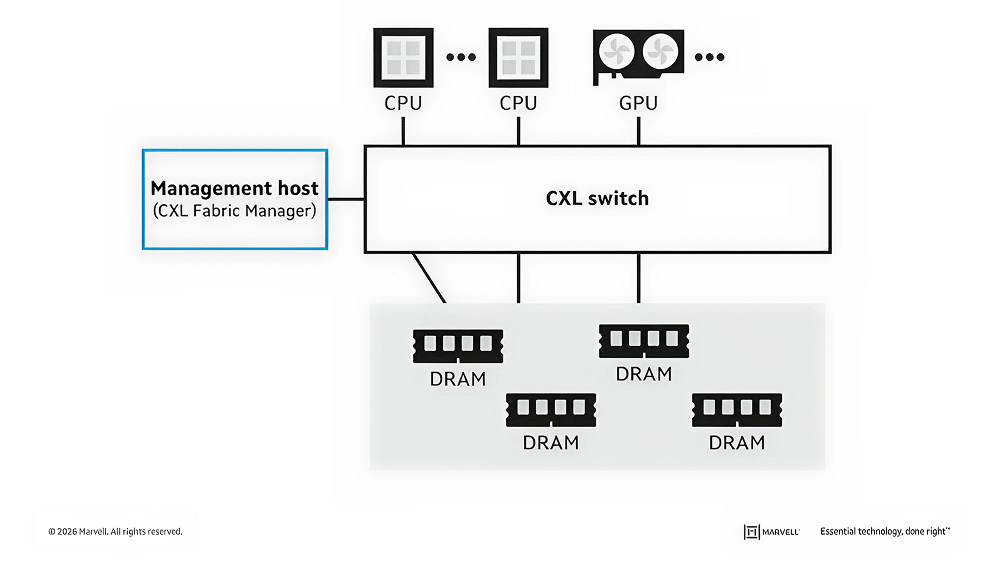
All for one and one for all: rather than dedicated to a single XPU, DRAM becomes a pooled resource for greater utilization.
An award-winning 2025 paper from Alibaba Cloud and XConn demonstrated how CXL switches used in conjunction with PolarDB CXL, a disaggregated memory system for cloud-native databases, can improve throughput by 2.1x with memory pooling and by 1.55x with CXL memory sharing.
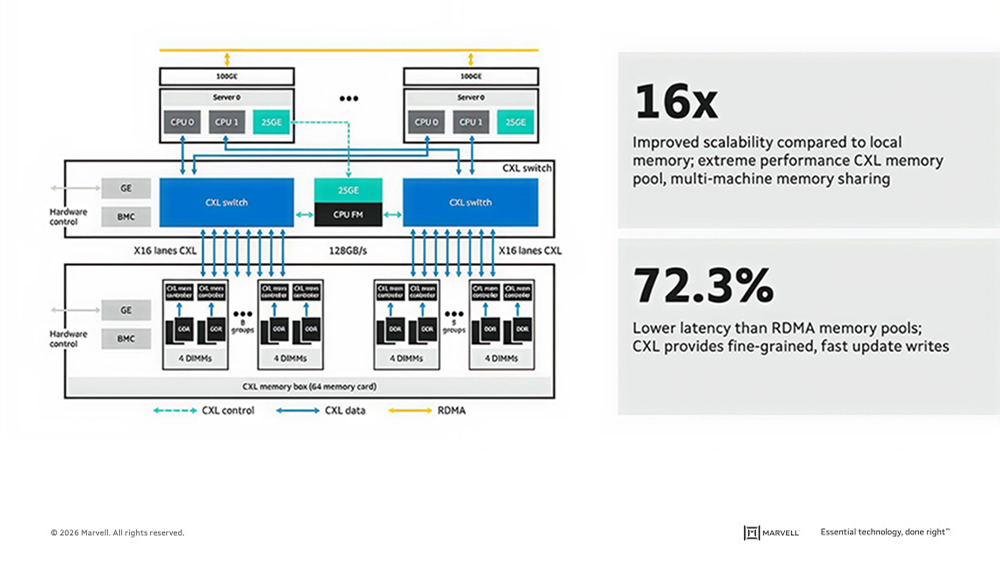
The configuration below shows a system with four CPUs using two CXL switches to link to a pool consisting of 16TB additional capacity. Sharing memory delivered 16x better scalability than local memory and over 72% lower latency than remote direct memory access (RDMA) pooling (Source: Marvell data).
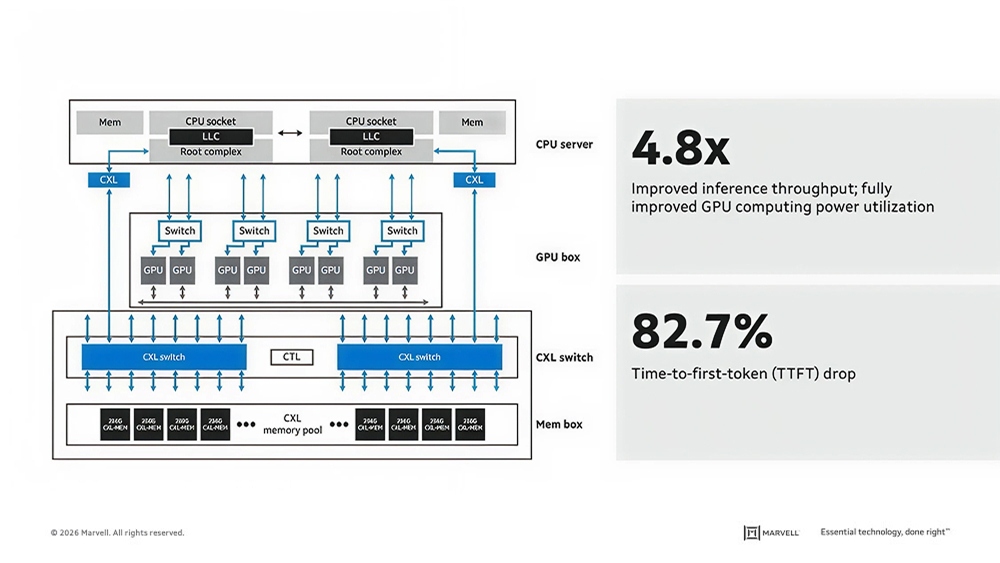
The figure below, meanwhile, shows a 16TB memory pool shared by eight GPUs and a two-CPU server. CXL pooling improved inference throughput by 4.8x and reduced time to first token by 82.7% (Source: Marvell data).
Structera S achieves these results through a unique set of features including:
Marvell is also continuing to cultivate an ecosystem for CXL switching.
CXL: Strength Through Diversity
With Structera S, Marvell also becomes the industry’s first and only company with a CXL portfolio that spans all three CXL product categories: memory expansion, memory acceleration and memory pooling. Each approaches the memory wall challenge in a contrasting, but complimentary, way. All three can also co-exist in the same infrastructure.
CXL memory expanders, for example, are engineered for maximum capacity. Up to 12TB of memory can be added to a single processor through Marvell Structera X. Even relatively modest amounts of additional memory can make a big difference. Marvell recently showed how adding 128GB of memory with a single Structera X can speed up inference tasks like time to first token by nearly 4x.

A populated Structera X board with Structera X controllers for DDR4 (top) and DDR5 (bottom).
Structera X memory expanders can also be coupled with repurposed/recycled DDR4 memory to slash component costs and e-waste.
Meanwhile, CXL memory accelerators, a Marvell first, support fewer terabytes but include server processors to perform near-memory computing. Benchmarks show systems with Marvell Structera A, which contains 16 server processors, can conduct 5x more vector searches per second or perform more queries per second at a lower latency than a standard system relying on its system memory.

By increasing the size of the KV cache, a Structera A memory controller accelerates vector searches at OCP in 2025.
The advantages of CXL can be evaluated in several ways: lower costs, lower power consumption, lower time-to-completion, etc., but they all lead to the same conclusion: CXL provides a foundation for flexibly harnessing one of the most critical assets inside data centers—memory—to enhance infrastructure performance.
# # #
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: AI infrastructure, Optical Interconnect, Optical DSPs, DSP, data center interconnect, AI
