
By Michael Kanellos, Head of Influencer Relations, Marvell
The opportunity for custom silicon isn’t just getting larger – it’s becoming more diverse.
At the Custom AI Investor Event, Marvell executives outlined how the push to advance accelerated infrastructure is driving surging demand for custom silicon – reshaping the customer base, product categories and underlying technologies. (Here is a link to the recording and presentation slides.)
Data infrastructure spending is now slated to surpass $1 trillion by 20281 with the Marvell total addressable market (TAM) for data center semiconductors rising to $94 billion by then, 26% larger than the year before. Of that total, $55.4 billion revolves around custom devices for accelerated compute1. In fact, the forecast for every major product segment has risen in the past year, underscoring the growing momentum behind custom silicon.
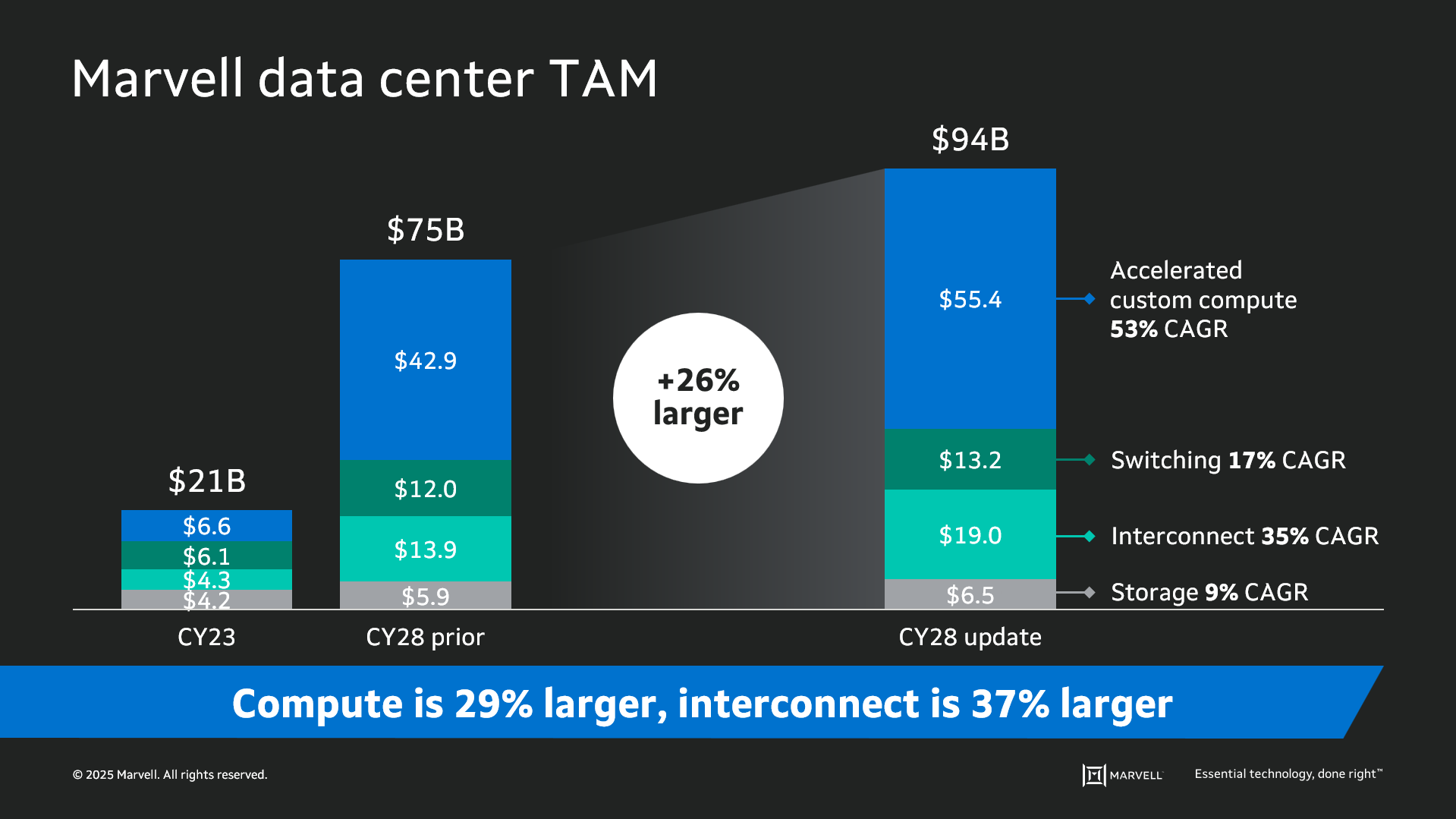
The deeper you go into the numbers, the more compelling the story becomes. The custom market is evolving into two distinct elements: the XPU segment, focused on optimized CPUs and accelerators, and the XPU attach segment that includes PCIe retimers, co-processors, CPO components, CXL controllers and other devices that serve to increase the utilization and performance of the entire system. Meanwhile, the TAM for custom XPUs is expected to reach $40.8 billion by 2028, growing at a 47% CAGR1.
By Kirt Zimmer, Head of Social Media Marketing, Marvell
The OFC 2025 event in San Francisco was so vast that it would be easy to miss a few stellar demos from your favorite optical networking companies. That’s why we took the time to create videos featuring the latest Marvell technology.
Put them all together and you have a wonderful film festival for technophiles. Enjoy!
We spoke with Kishore Atreya, Senior Director of Cloud Platform Marketing at Marvell, who discussed co-packaged optics. Instead of moving data via electrons, a light engine converts electrical signals into photons—unlocking ultra-high-speed, low-power optical data transfer.
The 1.6T and 6.4T light engines from Marvell can be integrated directly into the chip package, minimizing trace lengths, reducing power and enabling true plug-and-play fiber connectivity. It is flexible, scalable, and built for switching, XPUs, and beyond.
By Nizar Rida, Vice President of Engineering and Country Manager, Marvell Canada
This blog first appeared in The Future Economy
AI has the potential to transform the way we live. But for AI to become sustainable and pervasive, we also have to transform our computing infrastructure.
The world’s existing technologies, simply put, weren’t designed for the data-intensive, highly parallel computing problems that AI serves up. As a result, AI clusters and data centers aren’t nearly as efficient or elegant as they could be: in many ways, it’s brute force computing. Power1 and water2 consumption in data centers are growing dramatically and many communities around the world are pushing back on plans to expand data infrastructure.3
Canada can and will play a leading role in overcoming these hurdles. Data center expansion is already underway. Data centers currently account for around 1GW, or 1%, of Canada’s electricity capacity. If all of the projects in review today get approved, that total could grow to 15GW, or enough to power 70% of the homes in the country.4
Like in other regions, data center operators are exploring ways to increase their use of renewables and nuclear in these new facilities along with ambient cooling to reduce their carbon footprint of their facilities. In Alberta, some companies are also exploring adding carbon capture to the design of data centers powered by natural gas. To date, carbon capture has not lived up to its promise.5 Most carbon capture experiments, however, have been coupled with large-scale industrial plants. It may be worth examining if carbon capture—combined with mineralization for long-term storage—can work on this smaller scale. If it does, the technology could be exported to other regions.
Fixing facilities, however, is only part of the equation. AI requires a fundamental overhaul in the systems and components that make up our networks.

Above: The server of the future. The four AI processors connect to networks through four 6.4T light engines, the four smaller chips on the east-west side of the exposed processor. Coupling optical technology with the processor lowers power per bit while increasing bandwidth.
By Kishore Atreya, Senior Director of Cloud Platform Marketing, Marvell
Milliseconds matter.
It’s one of the fundamental laws of AI and cloud computing. Reducing the time required to run an individual workload frees up infrastructure to perform more work, which in turn creates an opportunity for cloud operators to potentially generate more revenue. Because they perform billions of simultaneous operations and operate on a 24/7/365 basis, time literally is money to cloud operators.
Marvell specifically designed the Marvell® Teralynx® 10 switch to optimize infrastructure for the intense performance demands of the cloud and AI era. Benchmark tests show that Teralynx 10 operates at a low and predictable 500 nanoseconds, a critical precursor for reducing time-to-completion.1 The 512-radix design of Teralynx 10 also means that large clusters or data centers with networks built around the device (versus 256-radix switch silicon) need up to 40% fewer switches, 33% fewer networking layers and 40% fewer connections to provide an equivalent level of aggregate bandwidth.2 Less equipment, of course, paves the way for lower costs, lower energy and better use of real estate.
Recently, we also teamed up with Keysight to provide deeper detail on another crucial feature of critical importance: auto-load balancing (ALB), or the ability of Teralynx 10 to even out traffic between ports based on current and anticipated loads. Like a highway system, spreading traffic more evenly across lanes in networks prevents congestion and reduces cumulative travel time. Without it, a crisis in one location becomes a problem for the entire system.
Better Load Balancing, Better Traffic Flow
To test our hypothesis of utilizing smarter load balancing for better load distribution, we created a scenario with Keysight AI Data Center Builder (KAI DC Builder) to measure port utilization and job completion time across different AI collective workloads. Built around a spine-leaf topology with four nodes, KAI DC Builder supports a range of collective algorithms, including all-to-all, all-reduce, all-gather, reduce-scatter, and gather. It facilitates the generation of RDMA traffic and operates using the RoCEv2 protocol. (In lay person’s terms, KAI DC Builder along with Keysight’s AresONE-M 800GE hardware platform enabled us to create a spectrum of test tracks.)
For generating AI traffic workloads, we used the Keysight Collective Communication Benchmark (KCCB) application. This application is installed as a container on the server, along with the Keysight provided supportive dockers..
In our tests, Keysight AresONE-M 800GE was connected to a Teralynx 10 Top-of-Rack switch via 16 400G OSFP ports. The ToR switch in turn was linked to a Teralynx 10 system configured as a leaf switch. We then measured port utilization and time-of-completion. All Teralynx 10 systems were loaded with SONiC.
By Nicola Bramante, Senior Principal Engineer
Transimpedance amplifiers (TIAs) are one of the unsung heroes of the cloud and AI era.
At the recent OFC 2025 event in San Francisco, exhibitors demonstrated the latest progress on 1.6T optical modules featuring Marvell 200G TIAs. Recognized by multiple hyperscalers for its superior performance, Marvell 200G TIAs are becoming a standard component in 200G/lane optical modules for 1.6T deployments.

TIAs capture incoming optical signals from light detectors and transform the underlying data to be transmitted between and used by servers and processors in data centers and scale-up and scale-out networks. Put another way, TIAs allow data to travel from photons to electrons. TIAs also amplify the signals for optical digital signal processors, which filter out noise and preserve signal integrity.
And they are pervasive. Virtually every data link inside a data center longer than three meters includes an optical module (and hence a TIA) at each end. TIAs are critical components of fully retimed optics (FRO), transmit retimed optics (TRO) and linear pluggable optics (LPO), enabling scale-up servers with hundreds of XPUs, active optical cables (AOC), and other emerging technologies, including co-packaged optics (CPO), where TIAs are integrated into optical engines that can sit on the same substrates where switch or XPU ASICs are mounted. TIAs are also essential for long-distance ZR/ZR+ interconnects, which have become the leading solution for connecting data centers and telecom infrastructure. Overall, TIAs are a must have component for any optical interconnect solution and the market for interconnects is expected to triple to $11.5 billion by 2030, according to LightCounting.
